
- 머릿글
제 블로그가 또 몇 개월간의 공백기를 맞았지만, STA+C때문에 미친 듯이 바빴던 2학기였기에 양해 부탁드립니다. 죄송합니다. 작성하지 못했던 몇 개의 글들을 오늘부터 벼락치기로 작성할 예정입니다.
- 데이터 가공
'알레르미'는 방대한 양의 식품 데이터가 필요했다. 당연하게도 식품 알레르기 정보를 제공해야 했으니 그랬다. 여기서 문제가 생겼다. 알레르미는 서버가 있었기 때문에 API로 필요한 데이터만 제공받을 수 있었다. 그런데 Allergist는? 인터넷 사용이 불가능하다.
다른 방법도 당연히 있다. 로컬 DB에 식품 데이터를 저장하는 것이다. 하지만 그것도 한계가 있다. 한국의 식품 데이터는 해봐야 13,000여 개였다. 그런데 미국은? 한국보다 땅덩어리가 수십 배 차이나는 미국인데 당연히 데이터의 양이 미친 듯이 방대했다.

원본 식품 데이터는 2GB대였다. 중복 데이터 클러스터링을 마치니 784.5MB가 되었다. 하지만 Swift Student Challenge 결과물의 크기 조건은 25MB였다. 택도 없었다. 벌써부터 막막해지기 시작했는데, 무언가를 떠올리고 pandas를 켰다.

일단 원본 데이터에서 필요 없는 칼럼을 날렸다. 고유 id와 칼로리 등, '식품 알레르기 제공'이라는 핵심 기능 구현에 필요가 없는 데이터는 모조리 날려버렸다. 이렇게 과감하게 칼럼을 날릴 때마다 용량이 점점 줄어들었다. '제조사', '이름', '원재료'만 남겼다.
그래도 용량이 300MB가 넘었다. 이대로는 안된다고 생각했고, 더 과감하게 데이터를 잘라내기 시작했다. 이 때 생각한 방법은 알레르기 정보를 미리 분석해서 열거형, 즉 숫자의 배열로 저장하는 방법이었다. '알레르미'도 비슷한 방식을 사용했었다.
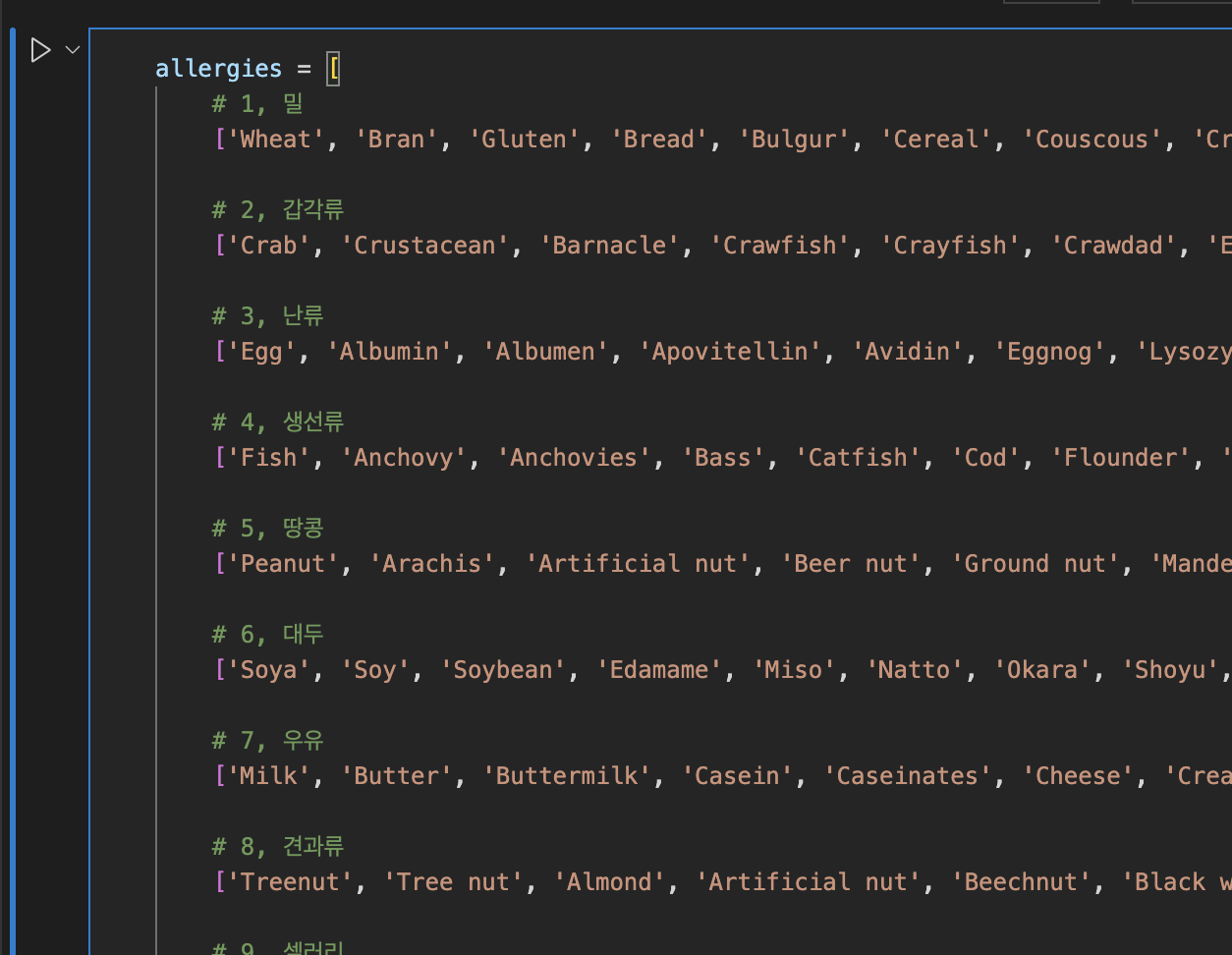

우선 원재료 경우의 수를 수집했다. 원재료 칼럼의 값을 콤마로 나누고, 나온 값을 클러스터시킨 후 미국 현지의 알레르기 정보 분류법칙에 의거해 해당되는 알레르기의 숫자의 배열을 구했다. 예를 들어서 밀은 1, 갑각류는 2. 이 두 알레르기가 있으면 [1, 2]였다.
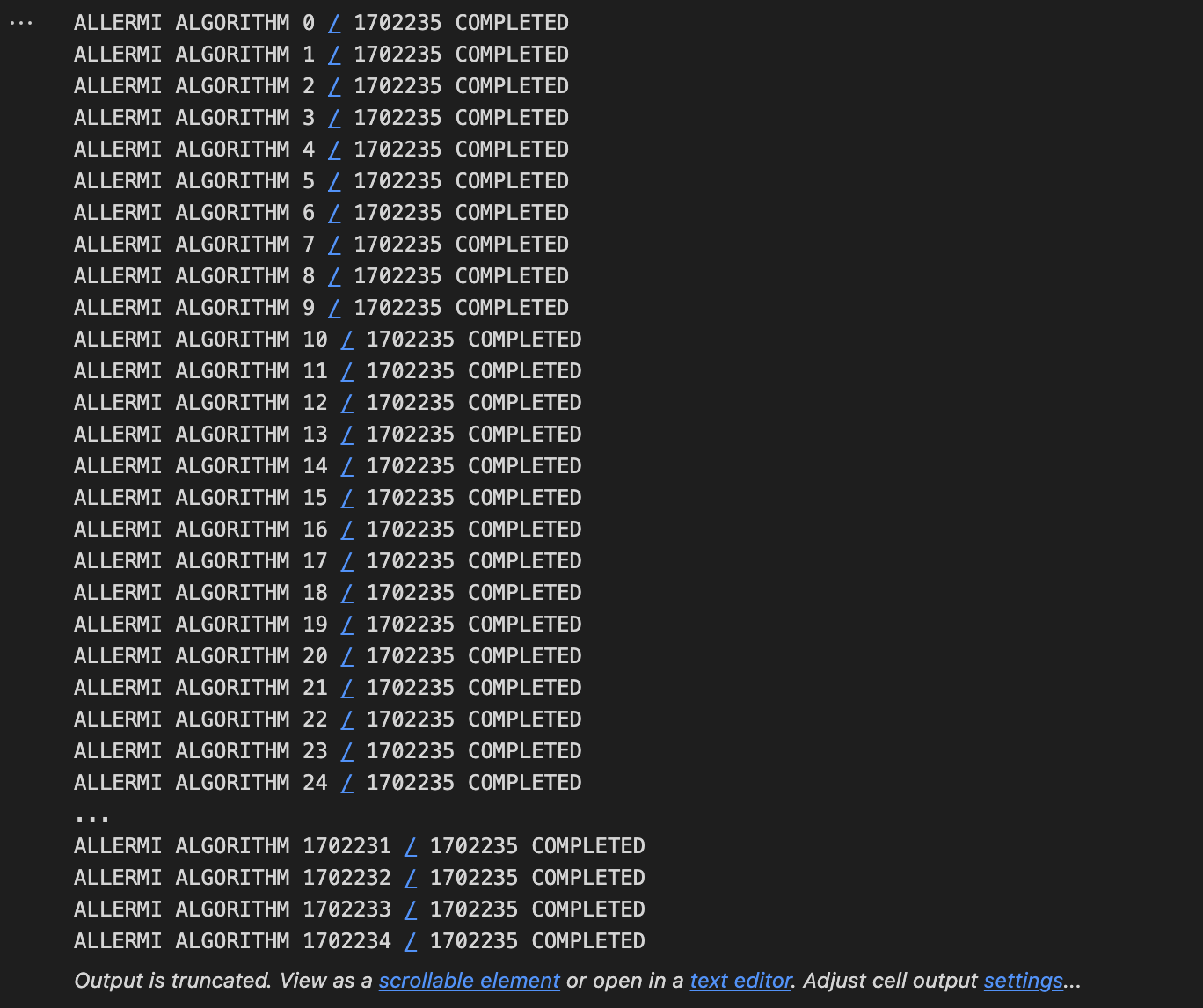
이 과정에서는 '알레르미' 개발 때 사용했던 '알레르미 알고리즘'을 재활용하였다. 역시나 잘 작동하는 모습이었지만, 데이터의 양을 보면 정말 무시무시하다. 무려 1,702,235개의 식품 데이터였다. 용량은 순식간에 20MB가 되었다.
- 최적화
데이터 가공을 성공적으로 완료하고, 이제 싱글벙글 개발만 남았는데 또 하나의 문제가 생겼다. 바로 이 데이터를 '불러오는 것'. 심사위원들이 이 앱을 실행했을 때, 이걸 DB에 저장하든 어떻게 하든 데이터를 최초 로딩하는 과정은 필수였다.
일단 무작정 CSV파일을 불러오는 로직을 짰다. 그런데 데이터를 로딩하는 데 당시 최신이었던 내 아이폰 14에서 1분 이상이 걸렸다. '3분 안에 즐길 수 있는 앱'이라고 했는데 그 중 1분이 로딩 시간이 되는 건 용납이 안 됐다. 다른 방법을 찾았다.
.swift파일을 한개 만들어서 저 모든 데이터를 전역변수로 넣어봤다. 당연히 컴파일에 실패했다. 그 다음은 JSON이었다. JSON도 CSV 마찬가지로 1분 정도의 속도가 걸렸다. 이 때는 Core Data 사용 방법도 몰랐기 때문에 앞길이 막막해졌다.
여기서 머리를 굴렸다. '어떻게 로딩 속도를 줄일까?'에서 'Apple이 기본 제공하는 포맷을 사용하자'로 결론이 나기까지는 얼마 걸리지 않았다. 'Apple이 기본 제공하는 XML 기반의 포맷', 바로 plist였다. 예전에 해킨토시 한답시고 삽질했을 때 사용했던 바로 그 포맷이었다.

plist를 사용하니 로딩 시간이 성능에 따라 1~3초로 단축되었다. 이 정도면 기다릴 만한 시간이다.

그런데 또 하나의 문제는 plist도 XML 기반이기 때문에 용량이 컸다. XML이 CSV에 비해 용량이 큰 이유는 하나의 데이터마다 두 줄의 태그가 매번 중복으로 들어가기 때문이다. 20MB였던 CSV 데이터는 plist로 바꾸자마자 순식간에 80MB가 되었다.
하지만 시간을 돌이켜 보자. 최종 제출 포맷은 .swiftpm을 압축한 'zip'다. '압축'의 정의는 중복된 데이터를 이용해 용량을 줄이는 행위다. 그리고 plist는 '중복된 값' 때문에 용량이 크다. 그 말은, plist를 압축하면 극단적으로 용량을 줄일 수 있다!
내 이론은 맞았다. 데이터의 압축을 완료하자 용량은 19MB였다.
- 플로우
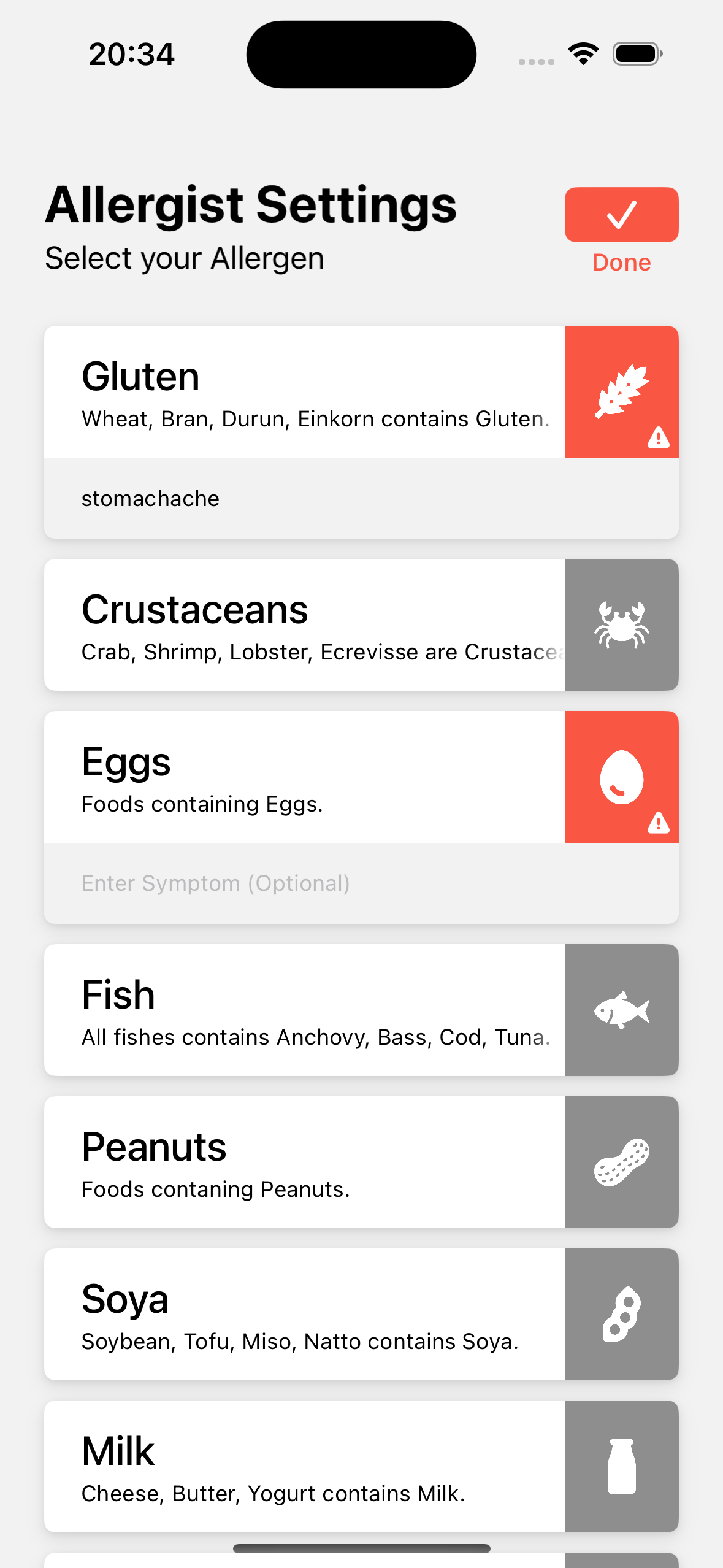

앱을 최초로 실행하면 좌측 화면이 뜬다. 바로 사용자의 알레르기 선택 화면이다. '알레르미'에서 조금 업그레이드시켜 노출 시의 증상도 입력할 수 있게 만들었다. 밀, 갑각류, 난류, 생선류, 땅콩, 대두, 우유, 견과류, 셀러리, 겨자, 깨, 아황산염, 루핀, 연체동물류가 있다.
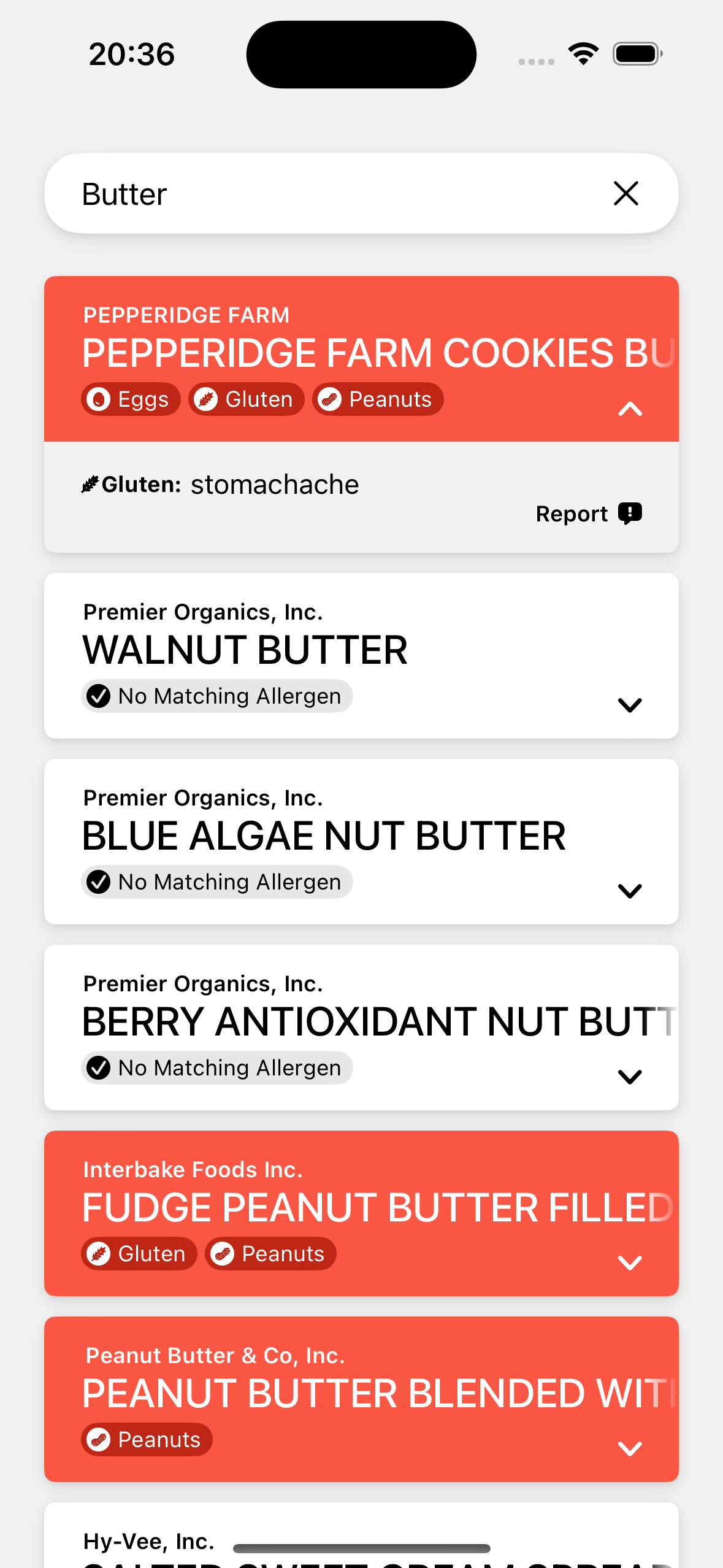
선택을 완료하면 중앙의 검색 화면이 뜬다. 이 화면은 알레르미의 디자인을 참고했는데, 역시 심플한 게 좋다. 하단에는 이전의 선택 화면으로 다시 진입할 수 있는 설정 버튼이 있다. 검색을 하면 우측 화면에서 데이터를 열람할 수 있다.
Apple은 건강 관련 앱에 보수적인 것을 고려해 잘못된 정보를 신고할 수 있는 기능도 넣었다. 그리고 터치할 수 있는 모든 컴포넌트에 Apple이 항상 강조하고 지향하기도 하는 접근성 기능인 접근성 레이블(accessibilityLabel)을 추가했다.
- 디테일
나는 앱에 애니메이션을 넣는 걸 좋아한다. 사용자의 눈을 즐겁게 해 화면에 남아 있는 시간을 간접적으로 늘려 주기 때문이다. 수상작 중에 게임이 많은 걸 보면 확실히 시각적으로 흥미를 끄는 앱을 만들어야 했다. SwiftUI의 장점을 활용할 시간이다.

정말 뼈를 갈아서 애니메이션을 넣었다. 단순한 스크롤에도, 단순한 터치에도 '이렇게까지 했구나'라는 생각이 들 수 있게 디테일에 미친 듯이 집착했다. 그리고 당연히 다크 모드도 지원했다. Apple이 좋아하는 모든 것들을 다 넣고 싶었다.
- 결말
개발을 완료하고 약 1달 후, 이메일이 날아왔다. 이 때까지도 솔직히 자신이 없었다. 최선을 다해 개발하긴 했지만 전 세계에서 350명밖에 선발하지 않기도 하고, 당시 iOS 개발을 시작한지 1년도 되지 않았을 때라 실력에도 자신이 없었다. 그런데...
우승을 했다. 2022년 5월에 iOS 개발을 시작하고, 2023년 5월에 Apple에서 상을 받았다.
- 후기
우승은 했는데 우승한 기분이 아니었다. 나름 Apple에서 상 받았는데 학교는 무덤덤한 반응이었다. 21년도 대마고 수상자는 보도자료까지 났는데, 나는 그런 거 없었다. 다른 사람들은 애플코리아에서 진행한 인터뷰도 했다는데 나는 그런 연락 못 받았다. 쓸쓸했다.

그래도 수상 후에 발이 넓어졌다. KWDC에서 따로 모임을 가지기도 했고, 연말에 수상자들의 모임 'Winner's Night'도 참가할 수 있었다. 나 혼자 미성년자였지만, 다들 좋은 분들이셔서 많은 지식과 정보, 그리고 경험을 얻었다.
개발하면서 미국은 정말 알레르기에 진심임을 느꼈다. 우선 알레르기 분류 체계가 굉장히 치밀했다. 생선은 '고등어'만 존재하고, 견과류는 '땅콩'으로 표기를 때우는 한국과는 달리 '견과류'와 '땅콩'의 분류를 확실히 하는 등 치밀한 모습을 볼 수 있었다.
그리고 1만 개를 조금 넘는 데이터 속에서도 오류가 엄청나게 발견된 한국 식약처 데이터와는 달리 170만 개의 방대한 데이터 속에서도 오타 하나, 오류 하나 없는 광경에 정말... 화도 나고 부럽기도 하고, 정말 미국에는 알레르미가 필요없을 것 같다.
읽어주셔서 감사합니다.
'스토리' 카테고리의 다른 글
| Apple에서 상을 받다 - 1 (0) | 2023.07.20 |
|---|---|
| 유난한 도전, 토스 방문기 (0) | 2023.02.11 |
| 해커톤 공포증 극복기 - 2 (完) (2) | 2023.02.10 |
| 해커톤 공포증 극복기 - 1 (0) | 2023.02.10 |
| 올 한 해를 마무리하며 - 작품 편 (完) (3) | 2023.01.01 |